
A new deep learning algorithm can predict the structure of proteins bound to a variety of other molecules such as drugs, fluorophores and metals. The work, which allowed researchers to design proteins to bind specific molecules, could be useful in fields such as enzymatic catalysis.
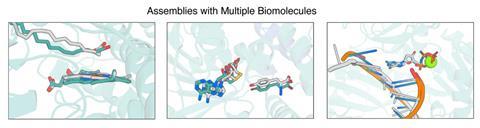
Proteins comprise thousands of atoms, so solving their structure using energy minimisation models like density functional theory is computationally unfeasible. Deep learning algorithms such as AlphaFold (developed by Google DeepMind) and RoseTTAFold (from the University of Washington’s Institute for Protein Design) have proved extremely useful, scouring known structures in the international Protein Data Bank to teach themselves how to solve unknown structures. ‘These deep learning methods are all working in terms of probabilities, not energies,’ says computational biologist David Baker, the Institute for Protein Design’s director.
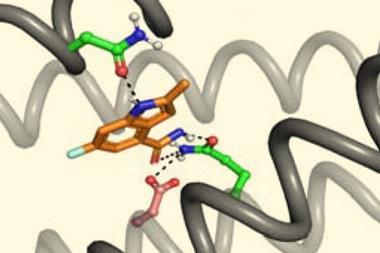
One complicating factor is that proteins in nature do not exist as isolated amino acid chains. ‘Some proteins don’t fold unless they bind to metals or other kinds of so-called cofactors that might be small molecules,’ says Nicholas Polizzi of Harvard Medical School in Massachusetts, US. ‘The ligand is often implied through AlphaFold or RoseTTAFold because they were trained on proteins that were crystallised and had their structure solved with the ligands bound.’ However, this prevents researchers from understanding the effect of the ligand or designing a protein to bind a specific ligand.
In the new work, Baker and colleagues developed a modified form of RoseTTAFold called RoseTTAFold All-Atom, which allowed them to combine amino acid-chain structures of the protein with atomic-based representations of the small molecule ligands. They obtained data on protein–small molecule structures, protein–metal complexes and proteins with covalently bonded amino acids from the Protein Structure Data Bank and used this to train an algorithm, enabling it to develop general predictive abilities. It predicted recently solved structures that weren’t in the training with a high level of accuracy. The researchers also used the model to design and experimentally synthesise proteins that bound three common ligands: the enzymatic cofactor haem, the cardiac disease drug digoxigenin and the light-harvesting molecule bilin.

The researchers are looking ahead to several applications, including the design of small molecule drugs and sensors. ‘We’re very interested in using this in the design of catalysts, where we can model the transition state for a chemical reaction and design a protein to stabilise it,’ says Baker.
Polizzi, who was not involved in the work, describes the work as a ‘milestone’. However, he cautions that one hurdle towards improving the method will be in sourcing more data to feed the algorithm. ‘Protein structure prediction has made such an advance because there’s billions of data points for protein sequence, but there isn’t the equivalent right now for small molecules,’ he notes.
Polizzi says that the latest version of RoseTTAFold appears to be ‘really good for trying to predict the structure of a protein with a molecule bound when you [already] know the molecule binds the protein’. However, he points out that many people will want to test whether a molecule will bind a protein at all. ‘I would still try it personally … but I wouldn’t trust those results blindly,’ he says.
References
R Krishna et al, Science, 2024, DOI: 10.1126/science.adl2528










No comments yet