
Proteins are generally considered to be programmed with a folding code: the sequence of amino acids along their chains determines how they fold into compact, functional shapes. Researchers in the US have now proposed that proteins also carry a second code, which acts as a kind of address label directing them towards cell compartments called biomolecular condensates.1
Biophysicist Rohit Pappu from Washington University in St Louis, US, who wasn’t involved in the work, believes that the idea ‘will stimulate a lot of discussion’– not least because ‘it generates numerous testable hypotheses’.
Condensates are blob-like aggregates, generally made of proteins and sometimes RNA molecules too. They range from hundreds of nanometres to several micrometres in size, and can form and dissipate spontaneously in cells.2 Some permanent and long-recognised cell structures, such as the nucleolus where ribosomes are formed, are now known to be condensates, and many others have been identified since such liquid-like structures were first reported in 2009.3 They seem to be involved in cell processes ranging from stress response to DNA repair and gene regulation, and factors that disrupt condensate formation have been implicated in diseases including cancer.
These blobs are held together by a wide range of molecular interactions, many of which are weak, transient, and rather unselective – for example, electrostatic interactions between charged molecular regions, hydrogen bonds, or hydrophobic forces. Other interactions can be quite specific and shape-complementary – for example, proteins that possess sequences for binding to RNA.4 A key question is why some proteins will segregate to particular condensates while others will not.
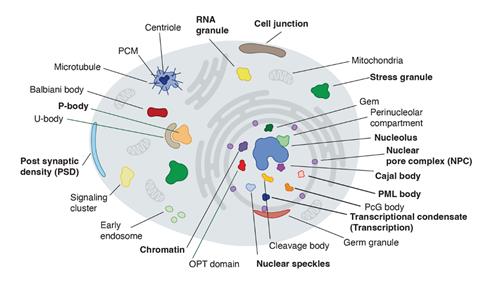
Biologist Richard Young and his colleagues at the Massachusetts Institute of Technology suspected that there might be a kind of hidden grammar or code in protein sequences governing this selectivity. They constructed a machine-learning model they call ProtGPS that looked for patterns in the partitioning of 5480 human proteins into 12 different kinds of condensate, according to sequence information stored in two public databases.
The researchers found that indeed ProtGPS identified sequence ‘codes’ that seemed to specify protein localisation in particular condensates. While factors such as protein-residue hydrophobicity or charge appear to underpin this behaviour, Young cautions that ‘the protein distribution code recognised by ProtGPS cannot be represented with a small number of conventional physicochemical components.’
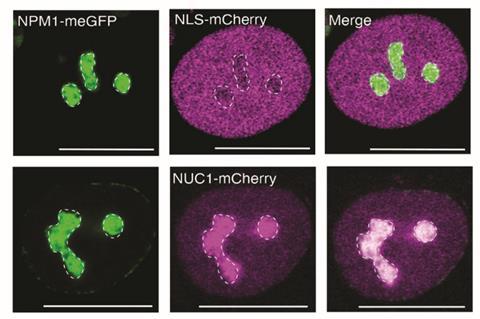
Young and his colleagues tested their code by showing that ten synthetic proteins assigned sequence signatures predicted to make them compatible with the nucleolus would indeed become enriched in that compartment when expressed in human cells. ‘Theoretical polymer chemistry convinces me that all proteins take part in condensate-related phenomena,’ says Young, who believes that the new code should thus apply to essentially all proteins.
Young says the findings should broaden ideas about how mutations can lead to pathogenic effects, which currently ‘rely primarily on thinking about changes in active sites or in shape and shape complementarity’. The findings might therefore have implications for drug development. ‘There are many disease mutations that affect condensate behaviors,’ adds Young. ‘And the ability to recognise these behaviours produces therapeutic hypotheses that promote drug discovery.’
Pappu notes that the idea of a kind of molecular grammar that controls the recruitment of specific proteins into condensates has been developing for several years. In part, he says, such partitioning is an issue of solvation: ‘The ‘solvent’ within a condensate is distinct from that of the coexisting dilute phase – the nucleoplasm or cytoplasm – and the properties of the solvent seem to be condensate-specific.’
According to Pappu, the new work shows that ‘the determinants of specificity – insofar as they are encoded in amino-acid sequences – can be gleaned, tested, and used to drive condensate-specific localisation to some degree’. He considers the results ‘an important first step’ towards that goal but adds that ‘there is a lot more to do and a lot that we do not know.’
References
1. H R Kilgore et al, Science, 2024, DOI: 10.1126/science.adq2634
2. S F Banani et al, Nat. Rev. Mol. Cell Biol., 2017, 18, 285 (DOI: 10.1038/nrm.2017.7)
3. C P Brangwynne et al, Science, 2009, 324, 1729 (DOI: 10.1126/science.1172046)
4. A S Holehouse & S. Alberti, Mol. Cell., 2025, 85, 290 (DOI: 10.1016/j.molcel.2024.12.021)











No comments yet