
A new initiative provides a way to assess how well text-generating AI models can answer chemistry questions. The researchers behind it show that large language models (LLMs) consistently out-perform human chemists across all topics, presenting their results in a new preprint report, which hasn’t yet been peer-reviewed. However, the assessment also highlights the limitations of these systems, including the LLMs’ inability to reliably apply chemical reasoning or accurately evaluate their own performance. The team hopes that ChemBench will be a ‘stepping stone’ to developing improved AI systems and more robust evaluative tools in future.
LLMs are trained on huge banks of text to predict the next logical word or sentence in response to a human prompt. As their capabilities have improved, chemists have begun to explore how they can be used as tools in research, for example in planning synthetic strategies, to predict molecular and material properties, or even to autonomously perform experiments using external tools.
However, despite their growing use, developers have a very limited understanding of how well LLMs actually perform in chemistry-specific tasks, relative to human chemists. Existing AI evaluation frameworks take an extremely simplistic approach to chemical problems, typically only testing a model’s ability to use or infer from existing knowledge. ‘For example, they can test if the model can predict a boiling point for a given [molecule] but this just isn’t enough to really assess if a model is at least a good starting point of a good chemist,’ says Kevin Jablonka, from Friedrich Schiller University Jena in Germany.
ChemBench, designed by Jablonka and his collaborators from a number of universities and tech companies, therefore takes a more holistic approach and is specifically tailored towards chemical applications. The team compiled more than 2700 questions covering eight broad topic areas across chemistry, with a variety of question types designed to evaluate performance in knowledge, reasoning and intuitive tasks. Each question was individually verified by human experts before inclusion, both to ascertain the quality and rank the difficulty. Care was also taken to ensure that none of the questions could be easily found online.
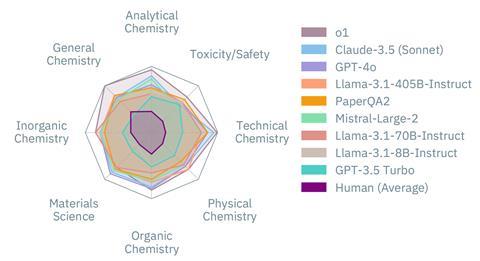
The team then evaluated the performance of 31 leading models on this corpus of questions, contextualising the results against the scores of 19 human specialists. In all cases, the LLMs outperformed human chemists: the leading model, OpenAI’s o1, achieved double the score of the top human and even the poorest model scored almost 50% higher than the average human chemist.
‘What they show here is tremendous,’ says Gabriel dos Passos Gomes, a chemical data scientist at Carnegie Mellon University in Pittsburgh, US, who wasn’t involved in the work. ‘An interesting consideration for the community is that depending on what you’re doing, you don’t need the most powerful model out there.’
However, breaking these results down, ChemBench revealed stark disparities in the models’ performance between topics, with the LLMs scoring well in general and technical topics but struggling with areas requiring specialist knowledge or spatial chemical reasoning such as safety and analytical chemistry.
According to Jablonka, this is partly due to the nature of these fields of chemistry. LLMs can’t interpret images directly and instead receive molecular information as names or Smiles – a machine-readable notation in which chemical structures are provided as strings of letters and numbers. ‘They somehow struggle to convert this text into something they can make an inference about, like symmetry or connectivity of certain atoms,’ he says. Specialist knowledge such as safety information can also be difficult for LLMs to access and interpret. ‘This type of data is often stored on specialist databases like PubChem and Sigma Aldrich, but even if the models have the tools to search these sources, the tool use is still unreliable,’ Jablonka adds.
But despite their overall poor performance in safety topics, the best models were in fact able to pass professional German safety certifications – a worrying result that Jablonka believes highlights a longstanding problem with how we measure performance using exams. ‘It raises the question how much of a good score is recall or memorisation versus reasoning and understanding,’ says dos Passos Gomes. ‘I think we’re going to have to take a good look at how we do evaluations of students and training and where we can integrate these tools into that process.’
Are you better at chemistry than an LLM?
Have a go at some example questions set by the ChemBench team:
1. Which of the following analytical methods is most appropriate for performing a survey analysis of a solid sample containing various metals?
2. Imagine an early virtual screening campaign setting (accounting for simple aspects such as oral availability and small molecular profile, but no other modalities such as covalency or bifunctionality). Which of the following two candidates would you prefer for further development?
3. What is the oxidation number of the metal in the compound [ZrF7]3–?
4. For NMR analysis, you need to digest a metal–organic framework in a strong acid to remove the linker and leave the metal clusters intact. Why would one choose HF over HCl for this purpose?
5. What is the reaction mechanism that describes the following reaction

6. The Born–Oppenheimer (BO) approximation is widely used in computational chemistry, but its accuracy can vary depending on the system. Among the following options, for which system is the Born–Oppenheimer approximation likely to be least applicable?
7. Which of the following statements is true about the different types of ideal reactors?
8. Pindolol and propranolol are (relatively nonselective) antagonists at β1 and β2 adrenoceptors. However, pindolol is a partial agonist, whereas propranolol is a pure antagonist. What follows from this?
The team also asked the models to provide confidence estimates in their answers. While some, such as Anthropic’s Claude 3.5 Sonnet, gave reasonably reliable predictions, others returned seemingly random results.
Jablonka notes that this disparity is an important consideration for how chemists should use and trust answers generated by AI, and probably results from post-training alignment of these models. ‘After training, you update the model to make it aligned with human preference, but that process destroys calibration between the model’s answer and accuracy estimate.’ As humans tend to prefer decisive answers, this post-training update encourages models to overstate their confidence in responses and present misleading estimates of their own accuracy.
These insights are vital to inform the design of future models and frameworks like ChemBench will be valuable tools moving forward. ‘This is incredibly well thought out and well done work,’ says dos Passos Gomes. ‘I believe strongly that the way forward for making the models more powerful and capable is by having proper reasoning in them. But if we cannot measure that, we will keep seeing mirages that they seem to be improving when they are not.’
For Jablonka, ChemBench is just the start and the team is already working on a follow up that will incorporate multimodal questions into the framework. ‘It’s not perfect, but we hope this will help developers build more reliable models in chemistry and to optimise the parts which are still underperforming,’ he says.
This article was updated on 16 June to include a reference to the research being published in Nature Chemistry
References
A Mirza et al, ar Xiv, 2024, DOI: arXiv:2404.01475v2
The preprint covered in this article was subsequently published in Nature Chemistry: A Mirza et al, Nat. Chem., 2025, DOI: 10.1038/s41557-025-01815-x















No comments yet