
A new protein sequencing method, which uses a biological motor to pull a protein through a tiny nanopore, could revolutionise protein analysis. The researchers at the University of Washington have also achieved a significant breakthrough in detecting post-translational modifications, including phosphorylation, to full-length protein structures at single molecule resolution.
The human genome has about 20,000 genes, yet researchers have identified 1 million different protein structures, or proteoforms. This diversity arises from genetic mutations and post-translational modifications – such as the addition of chemical groups or carbohydrate chains – that alter protein functions. These modifications play a key role in regulating complex biological processes and can also influence disease development, including cancer, Alzheimer’s and autoimmune disorders. Mapping this diversity could greatly enhance our understanding of cellular functions and extend opportunities for more specific disease interventions, but traditional methods struggle to deal with the three-dimensional structure of proteins.
To overcome this, Jeff Nivala’s lab, in collaboration with Oxford Nanopore Technologies, has developed a system for full-length protein sequencing using nanopore-sensing technology. ‘This innovative technique enables researchers to read long, intact polypeptide strands, offering new possibilities for understanding complex biological processes and diseases’, a spokesperson for Oxford Nanopore said.
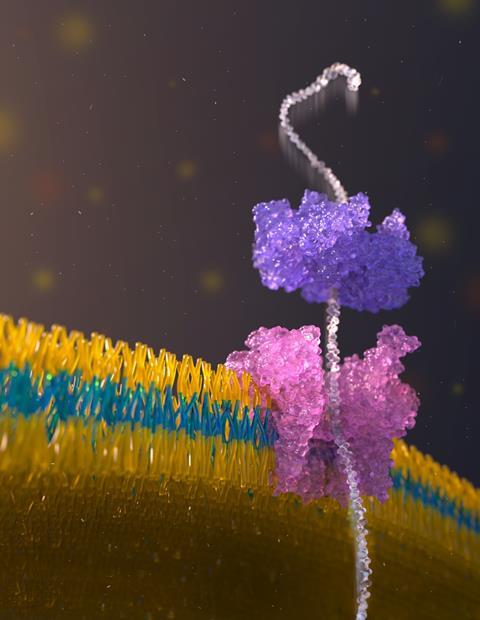
Nanopore-sensing technology, optimised for genomic DNA sequencing, works by drawing a long biopolymer through a biological channel – a nanopore – using an electric field. Structural variations are identified by measuring changes in the electric current applied across the nanopore. As different chemical groups cause different disruptions, this gives them a unique chemical signature that is used to decode the polymer sequence.
Before a protein can be passed through a nanopore for sequencing, its secondary and tertiary structures must be unfolded. Nivala’s team first modified a protein of interest by attaching a negatively charged ‘tail’ to draw the protein towards the pore when an electric current is applied. They also added a bulky ‘stopper’ sequence, which prevents the protein from passing completely through the channel. The stopper has a binding site for the enzyme ClpX, isolated from Escherichia coli, ‘which helps “unfold” and pull the protein through the nanopore’, explains Nivala. ‘ClpX has a unique stepping mechanism that allows it to move proteins in approximately two-amino-acid steps.’ The amplitude of the electrical current across the channel varies as the protein is pulled through the nanopore – a consequence of the amino acids present. These changes in amplitude can then be used to determine the protein’s sequence.
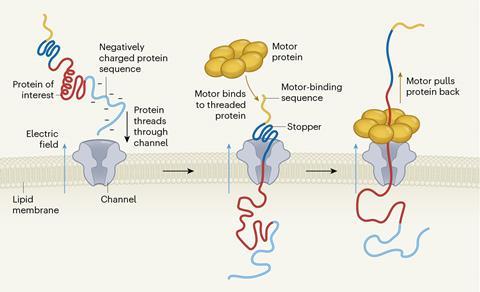
ClpX’s activity is not flawless, however, as it loses its grip on certain stretches of amino acids. Nivala’s team made use of this apparent imperfection to strategically insert ‘slipping sequences’ into the protein chains the researchers were attempting to sequence. ‘We could control the speed and direction of the protein’s movement, allowing us to reread sections and improve accuracy,’ says Nivala. ‘The ability to control this motion allowed us to develop a more detailed picture of the protein’s sequence.’
To interpret variations in electric current, the researchers developed an neural network named ‘aminocaller’. To demonstrate its potential, they systematically quantified and mapped enzyme-induced modifications in a protein that was 295 amino acids long, achieving over 98% accuracy and identifying more than 100 protein variants in a single experiment. This is a ‘huge step forwards’ notes Aleksei Aksimentiev at the University of Illinois, who was not involved in the project.
Despite its promise, the need to attach ‘tail’ sequences to the proteins and the added complexity of interpreting current measurements for unknown sequences poses significant challenges for high-throughput protein sequencing. ‘The challenge is to make something that can be used by anyone rapidly and easily without requiring them to have some kind of high-level expertise,’ says Yujia Qing, an organic chemist, at the University of Oxford, who was not involved in the study.
References
K Motone et al, Nature, 2024, DOI: 10.1038/s41586-024-07935-7













No comments yet