Screening reveals thousands of ‘undrugged, yet druggable’ proteins
By  Andy Extance2024-04-29T14:00:00
Andy Extance2024-04-29T14:00:00
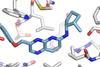
Collaboration involving Pfizer develops freely accessible AI tool to probe protein–compound interactions
By screening 407 compounds directly in cells scientists in Austria and the US have found that they bound with 2305 proteins not previously known to have any such interactions. Georg Winter at the Centre for Molecular Medicine (CEMM) of the Austrian Academy of Sciences in Vienna and colleagues used the large compound collection to create an openly accessible dataset. With that data, they then taught a machine learning system to accurately predict how promiscuously the compounds bind with proteins, and showed it could readily predict other properties.