Algorithm could also help unravel poisoning or environmental contamination cases
A machine-learning tool has outmuscled standard animal tests in predicting a chemical’s toxicity. Scientists in the US mined a large database of chemicals to build links between chemical structures and toxic properties. They then showed its worth: by predicting the toxicity of unknown compounds.
‘Artificial intelligence based on the big data set of toxicants is actually better than the animals at identifying toxic substances,’ Thomas Hartung of Johns Hopkins University told the Euroscience Open Forum (ESOF) in France, last week.
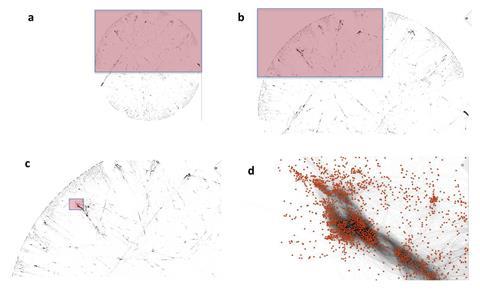
The computerised toxicity gauge was on average 87% accurate in reproducing the consensus from animal toxicology tests across nine common tests. Any given animal test has an 81% chance, on average, of obtaining the same result. The nine tests consume 57% of all animals in Europe for toxicology, around 600,000 animals.
‘This [tool] is not only good for replacing these animals during the process of registering a substance,’ said Hartung. ‘It could be useful for finding the most poisonous substance to kill a spy, or inform a chemist not to synthesise a substance because it is a skin sensitiser and so not useful for the product they want.’
Animals undergo millions of chemical toxicity tests, often mandated by law to protect consumers. The most common alternative is ‘read across,’ a process whereby researchers predict toxicity of one chemical by comparing it to a known compound with safety data and a similar structure.
To improve this process, Hartung two years ago compiled a machine-readable database with around 10,000 compounds submitted as part of Europe’s Reach regulation (registration, evaluation, authorisation and restriction of chemicals). Now his team has generated a map of chemical structures and their toxicology and an algorithm to place a compound on this map, thus predicting toxic effects such as eye irritation or DNA damage.
‘This has the potential to be an incredibly useful tool for chemical assessment and design and for evaluating safer alternatives,’ says Joel Tickner, an environmental health professor at the University of Massachusetts Lowell, US. However, he warns that the ‘approach shouldn’t be seen as the only thing we need to consult, but should instead complement other types of data, such as genomics and in vitro studies.’
‘While Reach has been criticised by many scientists, it is only because of Europe’s very progressive substance safety legislation, and the data from it, that this informatics study has been possible,’ notes molecular toxicologist Mark Viant, from the University of Birmingham, UK.
‘The quality of models can only be as good as the quality of the data used to train the models. Under Reach, there remain grand challenges that Hartung’s promising approach cannot yet address, as the relevant toxicity data does not exist,’ adds Viant. An example is environmental hazard assessments, which often comprise of toxicity studies on only three species, he explains, whereas the knowledge obtained is meant to protect millions of species in the environment.
References
T Luechtefeld et al, Tox. Sci., 2018, DOI: 10.1093/toxsci/kfy152










No comments yet